
作者: DigiKey Editor
关键词:开发板,AI,大模型
本文介绍了如何通过使用三块开发板实现大模型的本地部署,为硬件工程师提供了切入大模型领域的实践指南。文章概述了大模型的定义与特性,详细阐述了部署大模型的两种形式,具体介绍了三块开发板的配置与项目实践。这些项目不仅展示了开发板部署大模型的可行性,也为新手入门提供了详细指导。
- 大模型火到出圈,但硬件工程师该如何切入?
- 想在开发板上跑大模型却找不到教程?
- 什么样的设备才能扛住大模型的“算力暴击”?
相关《大模型实战》系列课程视频,一次性讲透!请点以下图片到B站观看:

- 关于《大模型实战》系列课程:
2025年,是大模型大爆发的一年,火到就连我们父母们都知道,不会的上网问问AI。对于我们工程师来说,不仅可以使用大模型,还可以部署大模型。
本期介绍什么是大模型,以及部署大模型所需要的硬件平台等。
要部署大模型,得需要有开发板。以下介绍一些开发板,可以用于大模型的本地部署或者是远程调用API接口。

| 
|
DigiKey 零件编号 | DigiKey 零件编号 |

| 
|
DigiKey 零件编号 | DigiKey 零件编号 |

| 
|
DigiKey 零件编号 | DigiKey 零件编号 |

|
DigiKey 零件编号 |
大模型简单介绍
大模型是一个通过“海量数据”训练出来的“超级模仿者”,能像人类一样处理语言、图像甚至决策。大模型也可以理解为一个数学函数,输入问题,比如“怎么写情书?”,输出答案就会生成一封情书。
大模型“大”,一是指数据大,它是学习了整个互联网的书籍、论文、对话等等,相当于读了整个图书馆的书。二是指参数大,大模型内部的“脑细胞”也就是参数数量惊人,比如GPT3有1750亿个,一般常用多少B代表模型的总参数量,B是 billion,十亿。
现在的大模型是非常“聪明”的,它可以是一个数学天才,高考数据分秒中就能给出答案,也可以是个软件工程师,让它写一段代码,不在话下。
部署大模型的形式
除了平时工作中使用大模型之外,对于我们硬件工程师来说,还可以自己部署大模型。
大模型的兴起可以促使硬件工程师,去学习与之相关的新兴技术,比如深度学习、人工智能算法等,以及了解新型硬件架构如 AI 加速器、TPU等原理和设计方法,成为AI+硬件的复合型人才,扩展职业赛道。
大模型实战部署有两个方式:第一种调用API接口,第二是部署在本地。这两种有什么区别呢?这里整理了一些区别:
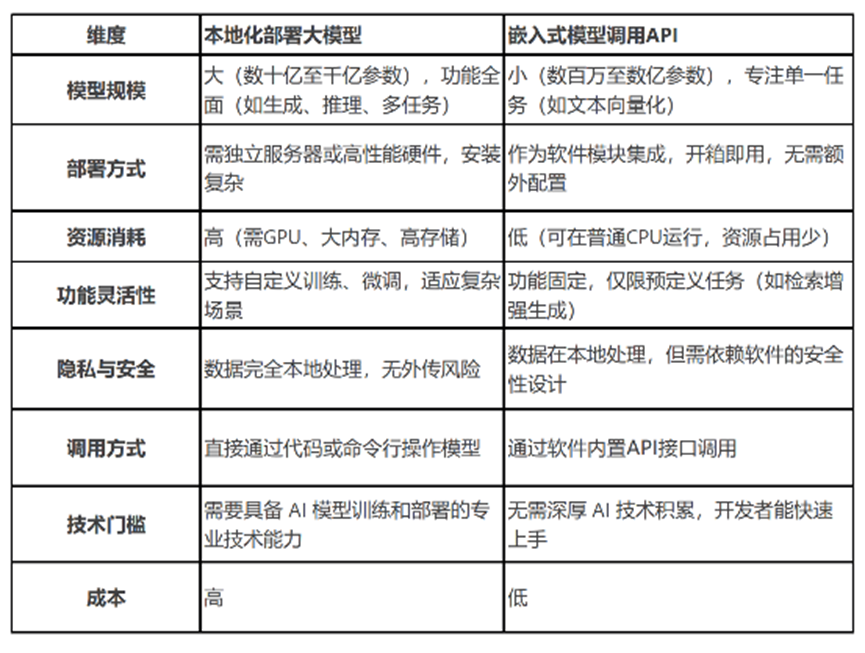
在开发板上部署大模型
在开发板上部署大模型有一定的要求的。前面我们说了大模型非常大,包含了大量的数据,超多的参数,这就需要开发板得有这么大的空间来存储这些内容,然后就是需要高性能的处理器了。
针对不同级别的大模型,我们使用3块可以部署大模型的开发板,并完成项目:
第一块,英伟达Jetson Orin Nano。边缘计算家族的新成员,前两年刚刚推出的,采用 6 核 Arm Cortex – A78AE 64 位 CPU,最高频率可达 1.5GHz,基于 NVIDIA Ampere 架构,搭载 1024 个 CUDA 核心和 32 个 Tensor Core 的 GPU,最高频率为 625MHz,提供高达40TOPS 的 AI 性能,其他的硬件配置如下图:

与前一代我们熟悉的Jetson Nano相比,Jetson Orin Nano继承了Jetson Nano的“小身材大能量”特性,从各个方面都是碾压之势,这次升级可以看得出来老黄还是很有诚意的。虽然Jetson Orin Nano算力已经不错了,但在Jetson Orin系列里,它还是小弟,属于入门级产品,在得捷官网,我们可以看到Jetson系列板卡可以购买。
Jetson Orin Nano高达40TOPS的算力,我们不能浪费了它强大的 AI 性能,什么复杂的深度学习模型,如 Transformer、BERT 等部署完全没问题,也可以实时处理多路高清视频流,轻松应对边缘 AI 场景下的各种任务。
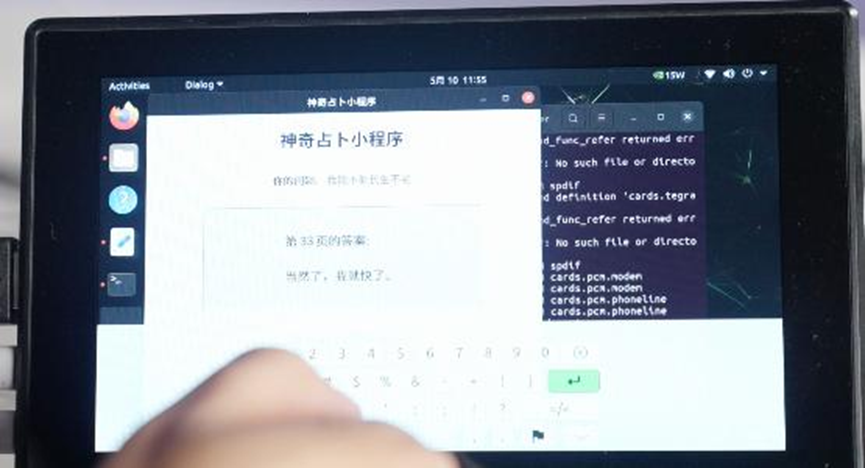
这不,我们就使用Jetson Orin Nano做了一个电子版的答案之书。在Jetson Orin Nano上安装Ubuntu系统,通过Ollama,直接拉取qwen2.5模型,生成「人生哲理」。你的任何问题,都可以来答案之书找答案。
第二块,DFRobot的Lattepanda sigma。sigma搭载的是 Intel Core i5 – 1340P 处理器,12 核心 16 线程,性能核最大睿频 4.6GHz,能效核最大睿频3.4GHz,支持高达 32GB 的双通道 LPDDR5 内存,带宽速度高达102.4GB每秒。而在外设接口方面,sigma更是有“一箩筐”,你就说你要啥,它全都有。

这次我们就利用了sigma的高性能和丰富的接口资源,做了一个贼有意思的项目:上帝说要有光,于是就有光。

具体是这样的,在sigma安装ollama,部署meta llama3.1:8b 和 谷歌的gemma3:4b大模型,麦克风采集音频并在本地解析为文本,然后调用本地ollama 模型api接口获取反馈,当识别到“上帝说要有光” 时,生成新的sketch并编译上传到leonardo开发板上,控制生成Arduino代码,Arduino发出控制指令,打开led灯。当识别到“天黑请闭眼”时,会关闭led灯。
当然,你可以换成任何的语音,只需让模型理解我们的语意就可以实现代码重新编写和上传的功能,就能控制灯的亮与灭。
第三块:树莓派5。有小伙伴可能有会质疑,前面两块板的性能是可以部署的大模型的,树莓派5性能够吗?树莓派5配备Broadcom BCM2712 2.4GHz 四核 64 位 Arm Cortex – A76 CPU,8GB 的 LPDDR4,单从CPU和存储上看,部署大模型确实不太够,但一些轻量化,体型较小的模型是可以支持的,比如我们部署的Gemma 3:2b大模型。
基于树莓派5设计一个本地AI助理,通过部署Gemma 3。语音输入之后,大模型进行数据处理,回复相应的内容,并翻译为英文,通过热敏打印机打印出来。
在本次大模型实战系列课程中,这3个项目都有详细的大模型部署过程,对于新手入门非常友好,跟着做就可以拥有一个属于自己的大模型系统了。本系列其余文章将于接下3周推出,敬请留意!
小编的话:
在开发板上部署大模型(尤其是轻量化后的参数模型)是当前AI落地的热点方向,但新手面临的核心挑战主要集中在硬件资源、模型优化、工具链适配、安全部署等几个方面。相信看完这个大模型实战系列课程,新手的难题会迎刃而解。您对大模型的本地部署有哪些疑问?对开发板的选用有哪些建议或疑问?欢迎留言,和DigiKey的朋友们一起分享交流!
******
如有任何问题,欢迎联系得捷电子DigiKey客服团队。
中国(人民币)客服
- 400-920-1199
- service.sh@digikey.com
- QQ在线实时咨询 |QQ号:4009201199
中国(美金)/ 香港客服
- 400-882-4440
- 8523104-0500
- china.support@digikey.com

到微信搜寻“digikey”或“得捷电子”
关注我们官方微信
并登记成会员,
每周接收工程师秘技,
赚积分、换礼品、享福利