
作者: DigiKey Editor
关键词:Jetson Orin Nano,开发板,答案之书
答案之书——随手一翻,随机获得一句人生建议,看似玄学却偶尔能带来灵感。《大模型实战》系列课程的第二节,就使用Jetson Orin Nano搭建了电子版的《答案之书》,让我们一起看看,大模型会给什么答案——
相关课程视频,请点以下图片到B站观看:

什么是电子版《答案之书》?
首先,我们要知道实物版答案之书的用法:使用者先想一个近期特别纠结的问题,例如是否要去表白、同事犯傻要不要告诉他、某支股票会不会涨等,然后拿着书专注 10 秒,再自然、随机地翻开这本书的一页,所看到的内容就是答案 。
本期在Jetson Orin Nano开发板上部署大模型,通过LED触摸屏+麦克风+扬声器,即可实现类似答案之书的功能:
1)语音提问,说出一个问题,比如说:我能不能一夜暴富?
2)开发板识别到语音,并通过麦克风语音说出:请输入你想知道的答案页数吧
3)屏幕上出现上面这句话,并出现输入数字的界面。
4)输入一个数字,点击确定,之后屏幕便出现答案,也就是这个页数对应的答案。
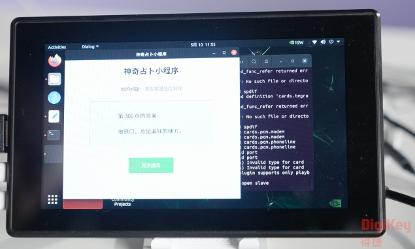
大模型在这个项目起到什么作用呢?实物版的答案之书由一个个如 “学会珍惜”“不要刻意压抑”“此时不宜” 等短句构成,局限性很明显,内容固定、缺乏互动性,而且无法结合具体问题给出动态反馈。
而电子版《答案之书》会根据语音内容,生成一个类似答案之书的答案,不是一本正经的回答问题,让我们在轻松愉快中得到答案。
为什么选择Jetson Orin Nano?
第一期视频中讲到,部署大模型要么调用云端的大模型接口,要么在本地。如果直接用云端大模型接口,响应延迟高,隐私性也存疑,所以选择在本地部署大模型,这对硬件开发板的性能提出了很高的要求。
Jetson Orin Nano 是英伟达(NVIDIA)面向边缘AI和机器人领域推出的嵌入式计算模组,它继承了Jetson Nano的“小身材大能量”特性,但性能直接碾压前代,堪称“边缘AI的核弹级升级”。

从下表中,可以看出与前一代Jetson Nano相比,Jetson Orin Nano各方面的性能,尤其是AI算力,大幅提升。
一句话总结:Jetson Orin Nano性能提升80倍,功耗仅增加50%,价格翻倍但性价比爆炸——“用两颗奶茶钱换一辆AI超跑”。
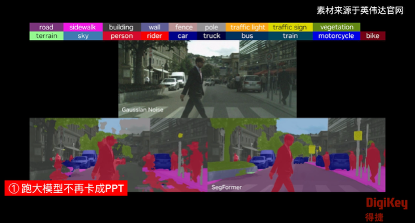
Jetson Orin Nano本地可以流畅运行Llama 3-8B、Qwen1.5-7B等大语言模型(FP8精度),问答延迟<2秒,跑大模型不再卡成PPT。原生支持Isaac Sim仿真工具链,训练到部署一条龙。
此外,Jetson Orin Nano可以实时处理多路1080P视频流:YOLOv8目标检测帧率50FPS+,比前代快20倍;还支持ROS 2 Humble,可同时处理激光雷达+摄像头+IMU数据,适合自主导航场景。Jetson Orin Nano还支持-25°C至80°C宽温工作,抗振动设计,直接塞进工厂机器毫无压力。
从软件开发生态上看,Jetson Orin Nano预装JetPack 6.0(基于Ubuntu 22.04),TensorRT、CuDNN等库,开箱即用。与NVIDIA TAO工具链无缝衔接,零代码实现模型迁移优化。
Jetson Orin Nano生态资源丰富,即使以前从未接触过Jetson系列板卡,也能从下面的资源中从容上手:
Jetson Orin Nano学习路径:
第一步:玩转NVIDIA Deep Learning Institute免费课程
第二步:复现Isaac Gym机器人仿真案例
第三步:用Metropolis框架落地智慧城市项目
推荐开源项目:
1)预训练模型全家桶:NVIDIA-AI-IOT/jetson-inference
2)超轻量系统镜像:Qengineering/Jetson-Nano-Ubuntu-Image
- Jetson Orin Nano + Qwen2.5模型:快速搭建AI答案之书
Jetson Orin Nano已安装Ubuntu系统,通过Ollama,直接拉取qwen2.5模型。
第一步,选择合适的大模型以及部署工具
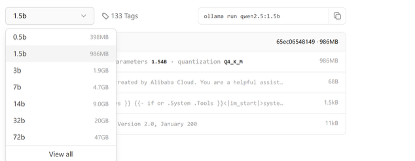
选择什么模型,需要考虑模型参数所占的内存,以及推理过程临时占用的内存。为了加快响应速度,选择qwen2.5模型。
模型选择好了之后,就是部署的工具,这里选择Ollama,一款开源的、专注于本地化运行大语言模型(LLM)的工具。简单来说就是“让你在自己的电脑或开发板上轻松玩转AI大模型”的神器。它解决了传统大模型部署的三大痛点:复杂的配置、高昂的算力需求和云端依赖,堪称“平民玩家的AI启动器”。
在Ollama官网,也可以查看模型类型,以及占用的内存需求,模型的执行命令。
https://ollama.com/library/qwen2.5
第二步:安装大模型
首先,需要安装jeston-containers,这是NVIDIA 为 Jetson 系列边缘计算设备(如 Jetson Orin、Jetson Xavier 等)提供的官方容器化解决方案,基于 Docker 或 NVIDIA Container Toolkit,旨在简化边缘 AI 应用的开发、部署和管理。
git clone https://github.com/dusty-nv/jetson-containers
jetson-containers/install.sh
然后,安装docker,并拉取ollama docker镜像
sudo apt install docker.io
docker pull ollama/ollama
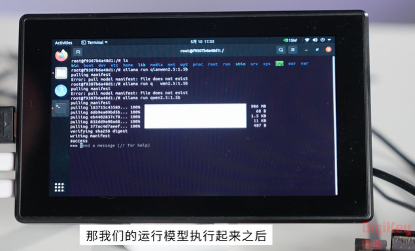
接着,运行docker以及qwen2.5:1.5b模型
docker run -itd –name ollama ollama/ollama
docker exec -it ollama bash.
ollama run qwen2.5:1.5b
第三步:与大模型进行交互
在docker中使用ollama运行大模型以后,下一步就是web页面或者软件app向模型发送问题,并接受回复,这就要启动Ollama容器时暴露端口,重新运行Ollama容器之后,就可以不通过终端命令行,让大模型远程问问题了。
docker run -d -p 11434:11434 –name ollama2 ollama/ollama
在主机上发送请求,并使用 curl 或 Python 代码与模型交互:
from fastapi import FastAPI
import requests
app = FastAPI()
@app.post("/ask")
def ask(prompt: str):
response = requests.post(
"http://localhost:11434/api/generate",
json={"model": "llama3", "prompt": prompt}
)
return {"answer": response.json()["response"]}
可以使用ollama list命令来确认,当前可用的模型列表。
使用流式输出:
import requests
import json
def clean_ollama_response():
response = requests.post(
"http://localhost:11434/api/generate",
json={
"model": "qwen2.5:1.5b",
"prompt": "用Python写快速排序代码",
"stream": True
},
stream=True
)
full_response = ""
for line in response.iter_lines():
if line:
try:
# 解码并加载JSON
chunk = json.loads(line.decode('utf-8').strip())
# 检查是否是有效响应
if "response" in chunk and chunk["response"]: # 这里不能有中文冒号
# 去除特殊字符和乱码
clean_text = ''.join(
char for char in chunk["response"]
if char.isprintable() or char in {'\n', '\t'}
)
print(clean_text, end="", flush=True)
full_response += clean_text
except json.JSONDecodeError:
print("! 遇到无效JSON数据,已跳过")
except UnicodeDecodeError:
print("! 遇到编码错误,已跳过")
return full_response
# 使用示例
if __name__ == "__main__":
clean_ollama_response()第四步:语音识别才是灵魂
由于Jeston Orin Nano的内存限制,无法使用NVIDIA官方提供的Riva完整的解决方案,为了识别精度以及节省内存,选择SpeechRecognition API接口来实现语音识别。
SpeechRecognition 是一个 Python 库,江湖人称“语音识别界的瑞士军刀”,能用几行代码就把麦克风听到的话转成文字,无论是做语音助手、声控设备,还是 “AI答案之书”,都能轻松搞定。
这是SpeechRecognition对应的代码:


此外,额外定制一个500*400的界面:
使用麦克风和音响接入Jetson Orin Nano开发板:

运行代码之后,就可以向“答案之书”进行提问了:
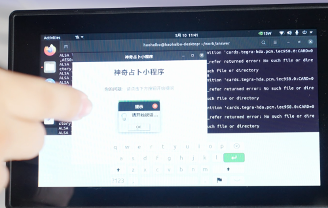
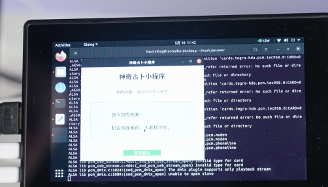
在文章开头的视频中,有“答案之书”的代码解析,感兴趣的小伙伴可以在视频13:00-19:00观看,这里就不再一一展示了。
下面就让我们问一问“AI答案之书”吧:
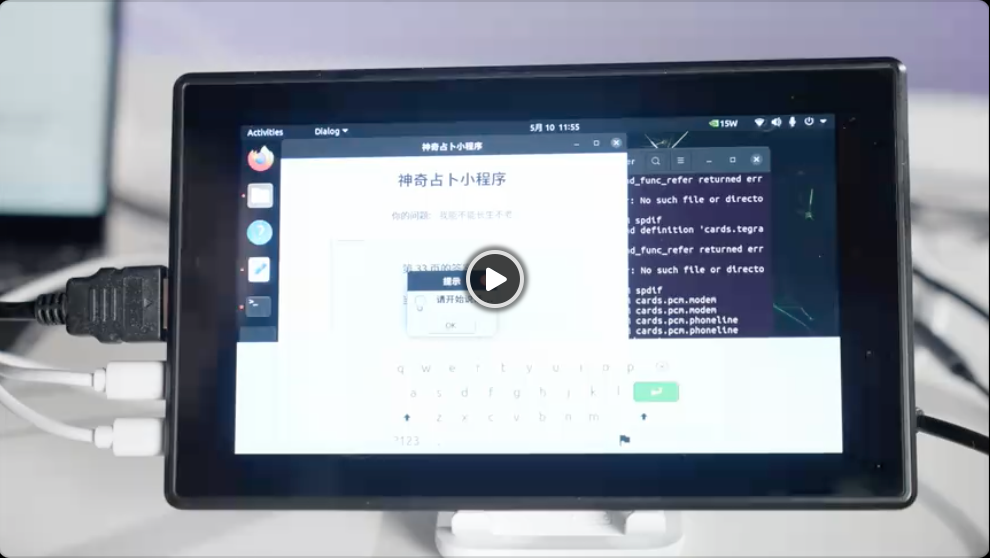
以上就是“答案之书”的设计过程了,希望通过上面的部署过程,大家都可以轻松在开发板上部署大模型了。
小编的话:
把 40 TOPS 的 AI 算力塞进7~15 W 的口袋型模组里,让“边缘小盒子”直接跑大模型,省掉了上云、加风扇、改板子的成本——Jetson Orin Nano以其卓越的性能、灵活的扩展能力、易用的软件生态以及合理的价格定位,在推动AI边缘计算的发展中扮演着重要角色。这篇文章直观的展示出Jetson Orin Nano的能力和价值。您是否也在使用Jetson Orin Nano开发部署AI项目,您在这个过程中有哪些经验或者疑问?欢迎留言,和DigiKey的朋友们一起分享交流!
******
如有任何问题,欢迎联系得捷电子DigiKey客服团队。
中国(人民币)客服
- 400-920-1199
- service.sh@digikey.com
- QQ在线实时咨询 |QQ号:4009201199
中国(美金)/ 香港客服
- 400-882-4440
- 8523104-0500
- china.support@digikey.com

到微信搜寻“digikey”或“得捷电子”
关注我们官方微信
并登记成会员,
每周接收工程师秘技,
赚积分、换礼品、享福利